
Michał Bortkiewicz
I’m a PhD student at the Warsaw University of Technology and a visiting researcher at Princeton University. I'm advised by Tomasz Trzciński, Piotr Miłoś and I collaborate closely with Benjamin Eysenbach. I work on making reinforcement learning practical and reliable at scale. My research focuses on unsupervised and goal-conditioned RL, representation learning for efficient exploration, and methods to mitigate catastrophic forgetting and improve plasticity.
News
Our paper "1000 Layer Networks for Self-Supervised RL..." received the Best Paper Award at NeurIPS 2025. 🎉
I will attend NeurIPS 2025 in San Diego! Feel free to reach out if you want to chat about RL 😀
Two papers accepted to NeurIPS 2025! "Contrastive Representations for Temporal Reasoning" and "1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities" (Oral) 🎉
Started my stay at Princeton University as a Visiting Student Research Collaborator 🐅
Two papers accepted to ICLR 2025! "Accelerating Goal-Conditioned RL Algorithms and Research" and "Learning Continually by Spectral Regularization" 🎉
Selected Publications
2025
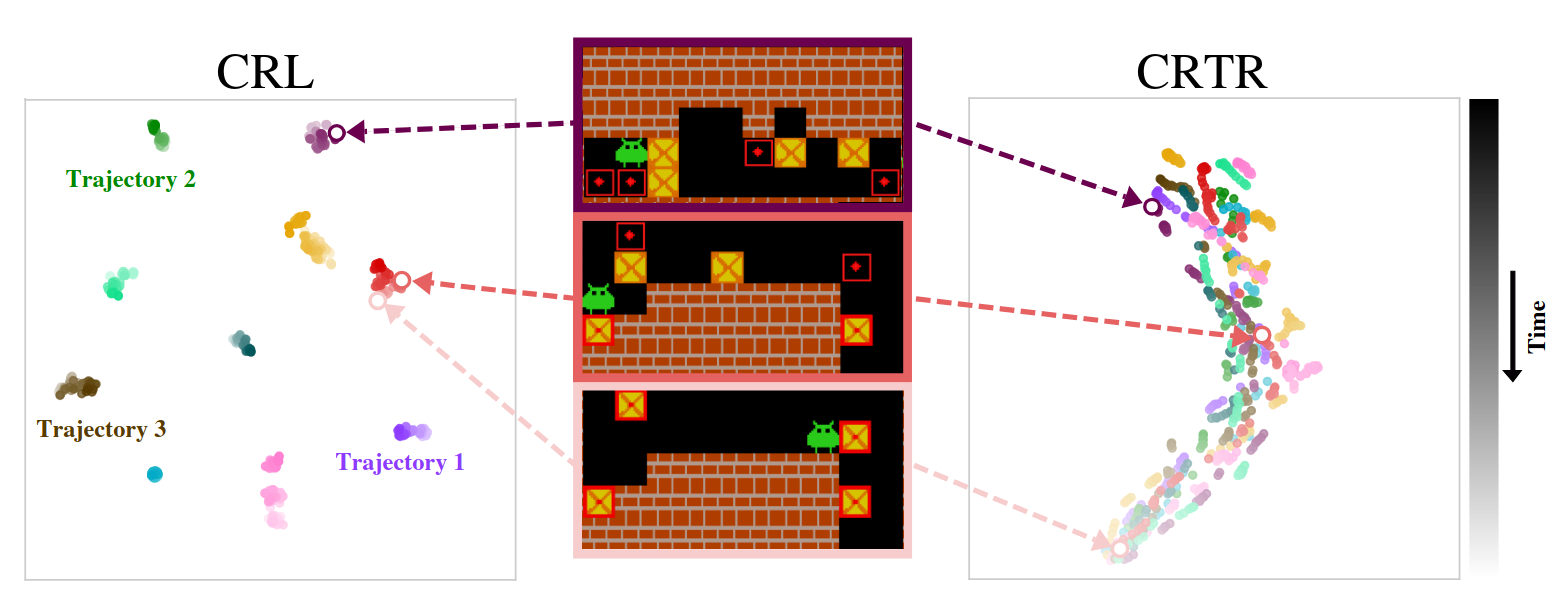
NeurIPS 2025: "Contrastive Representations for Temporal Reasoning"
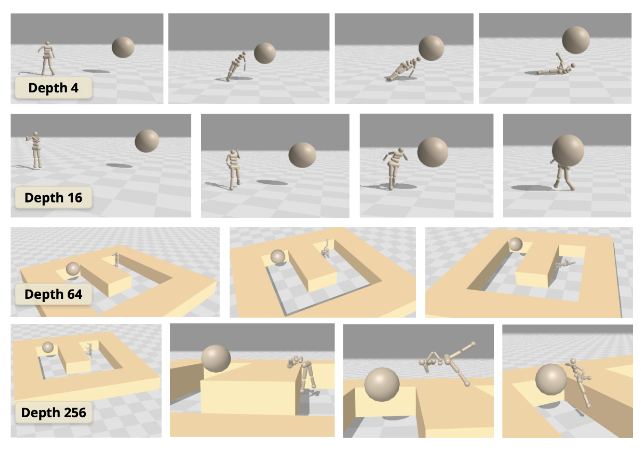
NeurIPS 2025 Oral: "1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities"
Best Paper Award
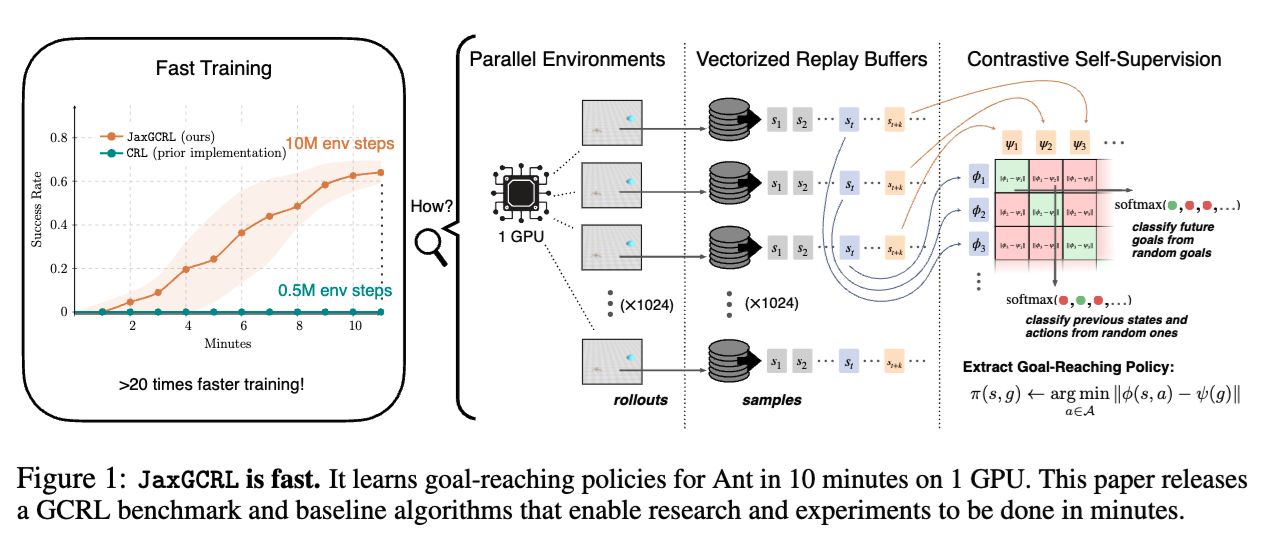
ICLR 2025 Spotlight: "Accelerating Goal-Conditioned RL Algorithms and Research"
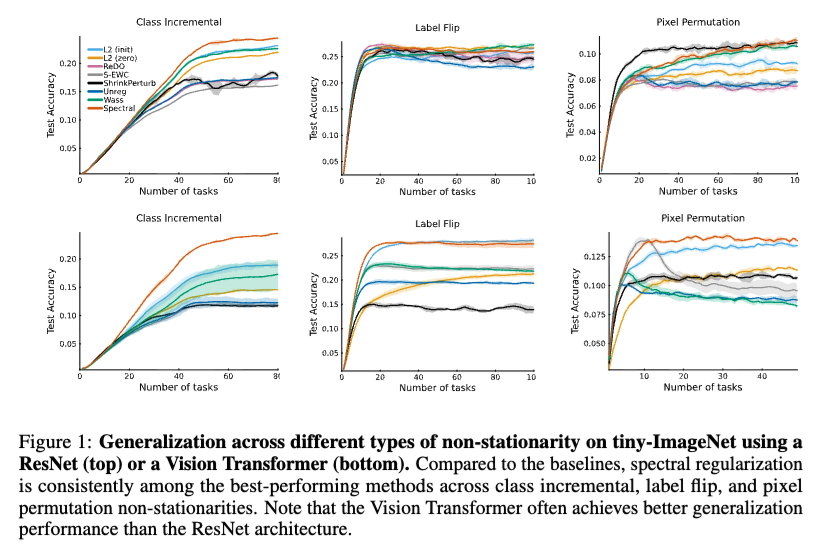
ICLR 2025: "Learning Continually by Spectral Regularization"
2024
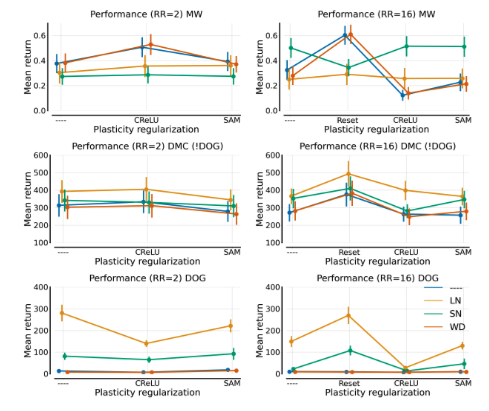
ICML 2024: "Overestimation, Overfitting, and Plasticity in Actor-Critic: the Bitter Lesson of Reinforcement Learning"
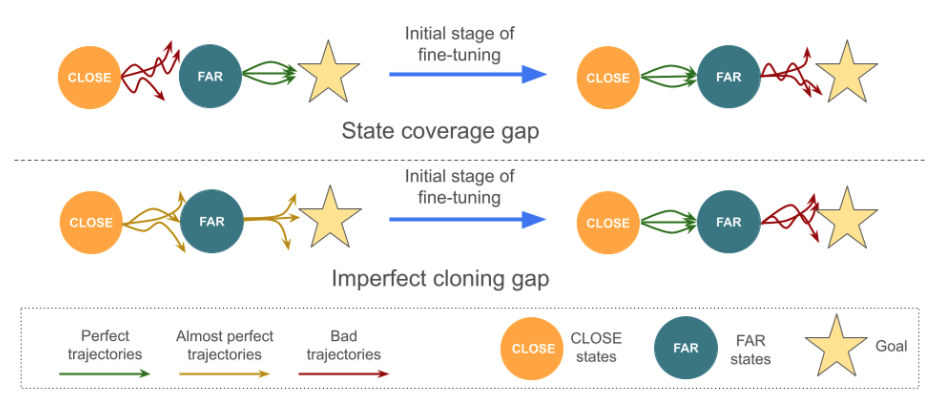
ICML 2024 Spotlight: "Fine-Tuning Reinforcement Learning Models is Secretly a Forgetting Mitigation Problem"
More available on Google Scholar.

